Entropy/IP: report for dataset C4
(Client IPv6 Addresses)
(How did we find this? Click to show the full report)
Entropy vs. 4-bit Aggregate Count Ratio (ACR)
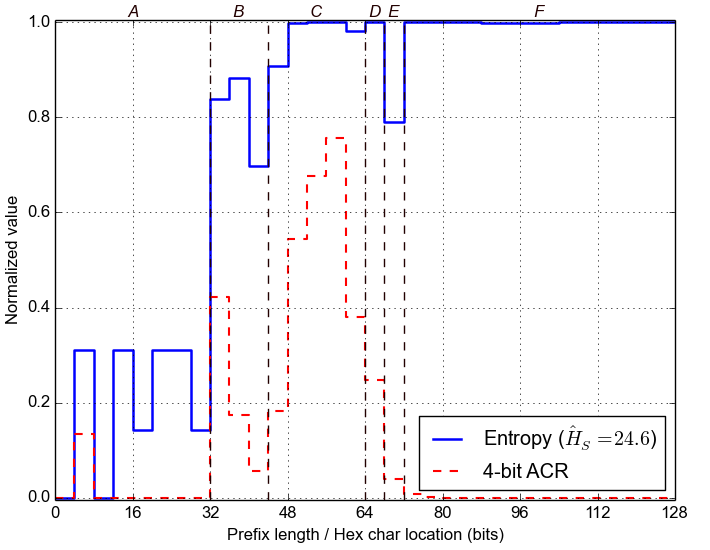
First, we estimate the Entropy for each nybble in the IPv6 addresses, across the whole dataset. For example, if the last nybble is highly variable, then the corresponding Entropy will be high. Conversely, the Entropy will be zero for nybbles that stay constant across the dataset. Below we plot the normalized value of Entropy for each of the 32 nybbles, along with the 4-bit Aggregate Count Ratio, which was introduced in Plonka and Berger, 2015.
Second, we group adjacent nybbles with similar Entropy to form larger segments, with the expectation that they represent semantically different parts of each address. We label these segments with letters and mark them with dashed lines in the plot below.
Segment Mining
Next, we search the segments for the most popular values and ranges of values within them. For that purpose, we use statistical methods for detecting outliers and the DBSCAN machine learning algorithm. We analyze distribution and frequencies of values inside address segments.
Below we present the results, with ranges of values shown as two values in italics (bottom to top). The last column gives the relative frequency across the whole dataset. The /32 prefixes are anonymized.
A: bits 0-32 (hex chars 1- 8)B: bits 32-44 (hex chars 9-11)
- 20010db8 66.80%
- 30010db8 19.72%
- 40010db8 13.48%
C: bits 44-64 (hex chars 12-16)
- 0b4 6.45%
- 1b8 5.80%
- 18c 4.54%
- 060 4.30%
- 080 4.27%
- 000 4.12%
- 248 3.78%
- 010 3.75%
- 144 3.75%
- 664 3.41%
- 919 2.96%
- 838 2.86%
- 96c 2.82%
- 49c 2.74%
- 5e0 2.71%
- 3cc 2.68%
- 2f0 2.62%
- 368 2.51%
- b72 2.36%
- f70 2.32%
- b71 2.31%
- 554 2.25%
- 8d1 2.15%
- * 444-f7a 22.54%
D: bits 64-68 (hex chars 17-17)
- e6eea 0.03%
- 25d96 0.02%
- eb12e 0.02%
- c50d2 0.01%
- 0bb1e 0.01%
- a930e 0.01%
- 200e2 0.01%
- 18632 0.01%
- 35afe 0.01%
- 42fac 0.01%
- * 00012-1f808 15.61%
- * 1f80f-d1a76 81.55%
- * d1a9e-fbfce 2.71%
E: bits 68-72 (hex chars 18-18)
- 8 6.46%
- 1 6.40%
- 0 6.34%
- c 6.34%
- * 2-f 74.45%
F: bits 72-128 (hex chars 19-32)
- 0 12.28%
- 1 12.26%
- c 12.24%
- 8 12.24%
- d 12.14%
- 4 12.08%
- 5 11.97%
- 9 11.93%
- * 2-f 2.88%
- * 00000000000002-fffe8af3de9c71 99.98%
Bayesian Network Structure
Next, we search for statistical dependencies between the segments. For that purpose, we train a Bayesian Network (BN) from data.
Below we show structure of the corresponding BN model. Arrows indicate direct statistical influence. Note that directly connected segments can probabilistically influence each other in both directions (upstream / downstream). Under some conditions, segments without direct connection can still influence each other through other segments: e.g., A can influence C through B if C depends on B and B depends on A (even if there is no direct arrow between A and C).
Learning BN structure from data is in general a challenging optimization problem. Hence, there might be more than one possible BN structure graph for the same dataset.
Conditional Probability Browser
Finally, below we show an interactive browser that decomposes IPv6 addresses into segments, values, ranges, and their corresponding probabilities. The browser lets for exploring the underlying BN model and see how certain segment values probabilistically influence the other segments.
Try clicking on the colored boxes below. You should see the colors changing, which reflects the fact that some segment values can make the other values more (or less) likely. For instance, in the Sample Report, you may find that clicking on J1 (i.e., the first value in segment J) makes segments C, D, F, H, and I largely predictable (see our paper for more examples).
You may condition the model on many segment values. Clicking on selected values un-selects them. Clicking on the red "Clear" above the color map un-selects them all. Below the browser we show the estimated proportion of the addresses matching your selection (vs. the dataset). If the browser cannot estimate the probabilities in a reasonable time, it asks before trying harder.
Candidate Target Addresses
Using the BN model, below we generate a few candidate target IPv6 addresses matching the selection above. Note that we anonymize the IPv6 addresses in this report.
As we show in the paper, this technique allowed us to successfully scan IPv6 networks of servers and routers, and to predict the IPv6 network identifiers of active client IPv6 addresses.